FlashMLA
Faster LLM Inference on Hopper GPUs

Description
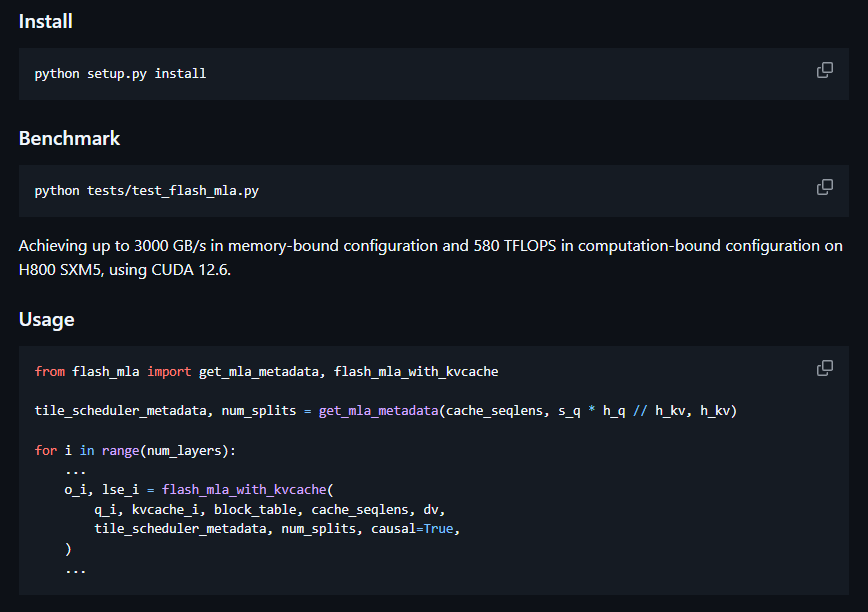
FlashMLA, from DeepSeek, is an efficient MLA decoding kernel for Hopper GPUs, optimized for variable-length sequences. Achieves up to 3000 GB/s memory bandwidth and 580 TFLOPS.
FlashMLA, from DeepSeek, is an efficient MLA decoding kernel for Hopper GPUs, optimized for variable-length sequences. Achieves up to 3000 GB/s memory bandwidth and 580 TFLOPS.